“‘O Deep Thought computer,’ he said, ‘the task we have designed you to perform is this. We want you to tell us….’ he paused, ‘The Answer.’
‘The Answer?’ said Deep Thought. ‘The Answer to what?’” - Douglas Adams, Hitchhiker’s Guide to the Galaxy
Enlarge

Photo by: Dan Seifert / The Verge
Technological advancements are making science fiction seem more and more plausible as reality. Nowhere is that more apparent than with modern day voice recognition technologies. From Siri to Google Assistant to Alexa, virtual assistants that can comprehend auditory commands are playing an ever bigger role in the way we interact with tech in our phones, offices, and homes. So, why is voice recognition becoming so prevalent, and how does it work?
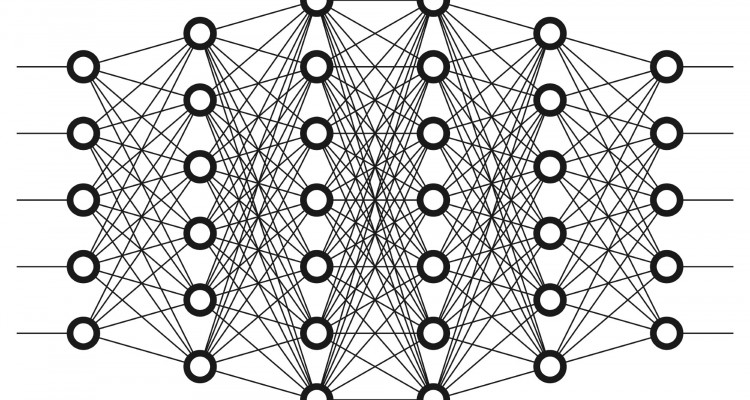
To start, it’s important to understand the basis of modern voice recognition: artificial neural networks. Like a neuron in a human brain, an artificial neuron in a neural network takes in an input, performs some computations, and releases an output. The difference? The output is in the form of vectors rather than electrical signals. Each link from input to neuron contains a weight by which the input is multiplied. So, a very simple adding neuron with inputs x1, x2 and weights w1, w2 respectively, would have the output x1*w1 + x2*w2. Inputs can also be linked to multiple neurons with different functions to create a neural network. The outputs of one neural network can then be fed in as inputs to another neural network, creating layers. The simplest neural networks, or shallow networks, consist of just three layers: an input layer, an output layer, and a single layer to alter the input in between. Deep learning is possible when multiple layers exist between the input and output layers, creating a deep neural network. These networks are more powerful, but are complicated, computationally-intensive models.
Modern voice recognition technologies use these multi-layered deep networks to process speech and create an output. They begin by recording the data from the sound waves produced by talking, reading data points from regular intervals from those waves (a process known as sampling), and then feeding these inputs into the neural network. These data points traverse through layers of the network, which transform them from vector inputs to eventually become probabilities of phonemes, or distinct units of pronunciation. To decide on a correct interpretation, previously recorded phonemes also influence later ones: for example, after deciding on the phonemes for “WATE”, the next letter would more likely b
[An artificial neuron is] like a neuron in a human brain... The difference? The output is in the form of vectors rather than electrical signals.
e read as “R” rather than “X.”
For these networks to perform accurately, they must also be trained using actual speech recordings with correct phoneme translations. Before the launch of Amazon Echo, thousands of hours of speech were recorded and transcribed to train its neural networks, whose weights and neurons were adjusted to minimize its error in comparison to the correct phoneme transcriptions. It is the high levels of accuracy created by deep networks put through this training process that has allowed modern voice recognition technologies to be so successful, with accuracy increases going from only 5-10% per year, to up to 30% in recent years. These improvements are the result of the amount of speech recording data now available, which has gone from mere hundreds of hours, to over 20,000 hours. The increased speed of computation also allows current deep networks to process and learn from recordings at the rate of hours within a single second. Finally, the development of a distributed model of training where different parts of a network are trained different machines, rather than the whole network on a single machine, has expedited the deep learning process.
And, as more and more people use technologies such as Alexa or Echo, the more data and voice recordings will be available for network training. Each time you ask Alexa to order a pizza, you add to the bank of auditory data that AI technologies can analyze, allowing voice recognition based assistants to continue to develop and improve.